
Import formats of Gargantext
For all types of imports
The files must be uploaded to the compressed archive format zip (.zip). Whether you have one or more files, you need all in one zip archive.
The corpus of import marks the beginning of an analysis, it operates from the page listing projects:
http://gargantext.org/projects/projectId
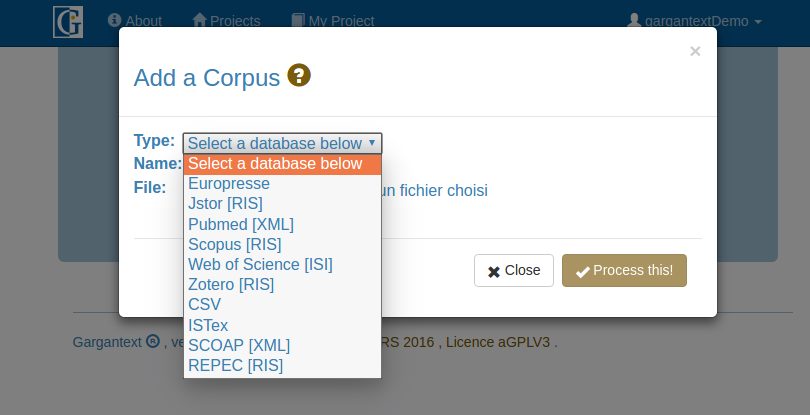
Types of import description
CSV
The CSV format Gargantext includes:
- A UTF8 character set
- Tab as the field separator
- Field delimiter with quotes (« )
It is highly recommended to use a free text editor such as LibreOffice or OpenOffice, some proprietary vendors tend to impose their CSV format.
- Under LibreOffice for example, when you ‘save as’ your document, click on ‘edit settings filter’
 Then choose the parameters as follows:
Then choose the parameters as follows:

- With Excel
- Open the file with Excel by selecting all cells (select the first cell and then Ctrl + A or Cmd + A on Mac)
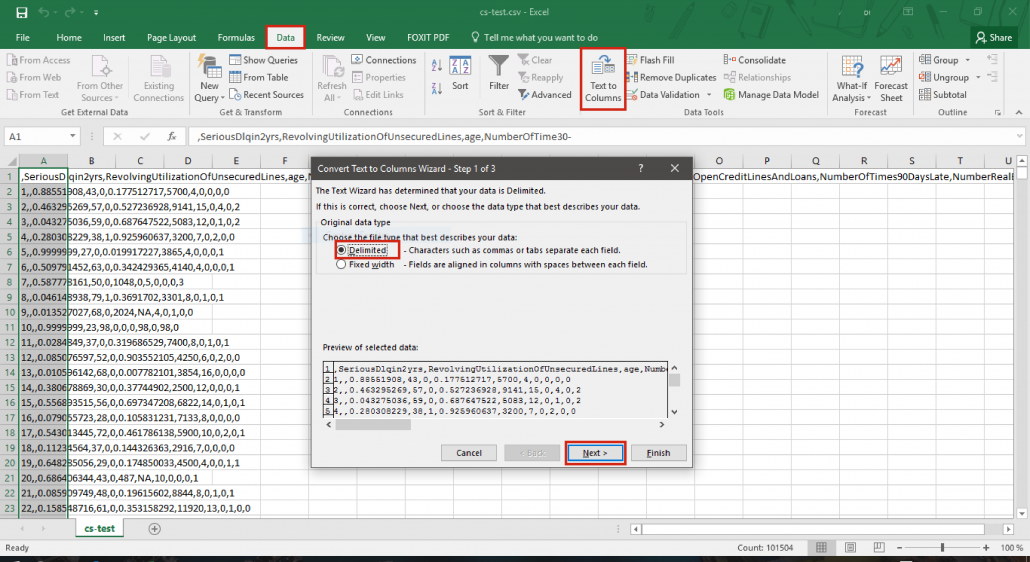
- Save the file by specifying it as a CSV file (.csv)
- Open the file with Excel by selecting all cells (select the first cell and then Ctrl + A or Cmd + A on Mac)

The file itself should contain the following fields with a first line of headers described in brackets:
– title of the document [title]
– content of the document [abstract]
– date of the document [publication_year]
– authors [authors]
– source of the document (ex : title of the journal) [source]
– month of the publication (if not indicated, put the number ‘1’) [publication_month]
– day of the publication (if not indicated, put the number ‘1’) [publication_day]
Compress the file as a .zip file before uploading to Gargantext.
Note that you can download any of your corpora to the latest CSV file format with the « export corpus » button at the top right corner of the document view.
If your CSV fails to load – trouble shooting
- check that you are uploading a zip file
- check that your csv is encoded with tab as separators. Sometimes, your text editor change without notifying the encoding,
- remove tab characters that are not column separators : open the document in a spread sheet editor, replace \t with spaces.
Web of Science (ISI)
People with a Web of Science Access can export the results of their research to analyze in Gargantext.
On the search results, choose ‘save to –other file format’
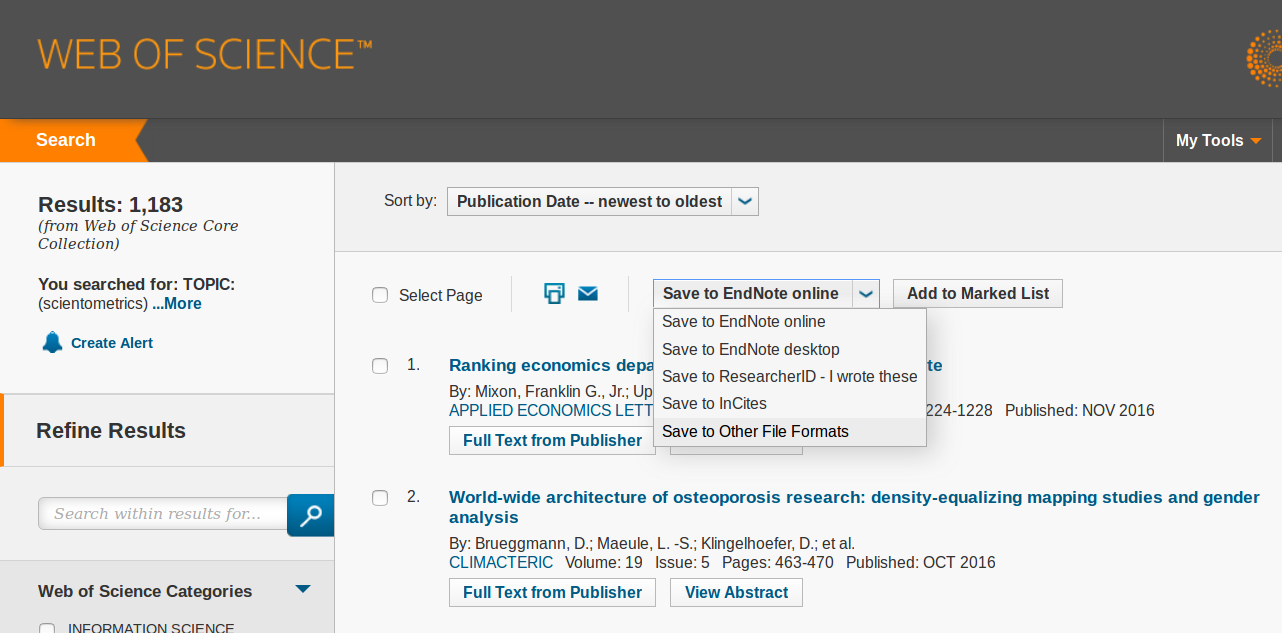
Then choose the fields as follows:
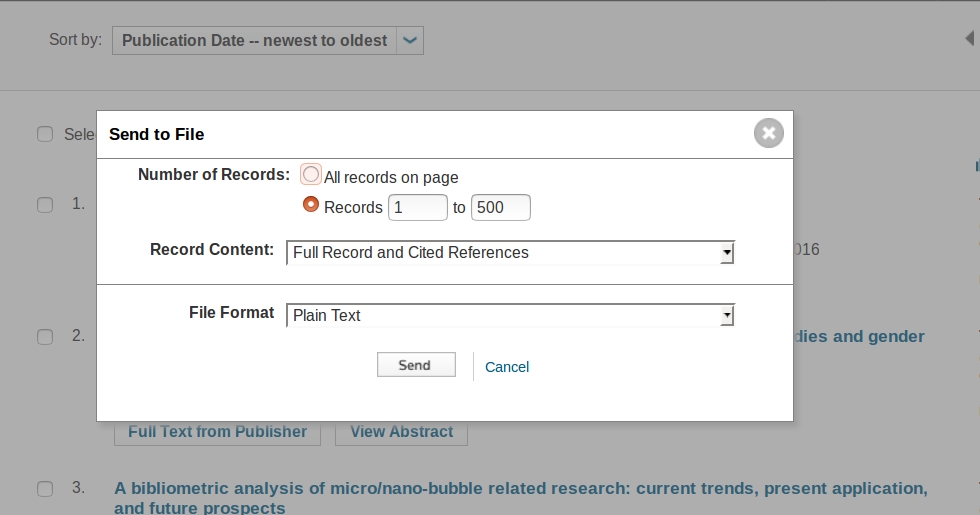
Compress all files obtained before uploading them on Gargantext.
PubMed
PubMed is the larger Scientific and medical abstracts database in open source from the National Center for Biotechnology Information. You can analyse set of articles metadata from PubMed through two distinct methods :
- ask Gargantext to retrieve the last 1000 items matching to your query (select « PubMed [XML] » in the add corpus drop down menu),
- Uploading yourself a zip file with PubMeb exported item from the NCBI website. In that case, you can analyze up to few 10k items (above 40k, you will have client side issues on Gargantext 3.x versions). To export PubMed items, enter a query in the search page, then click on « Send to > File > XML Format » as in the picture below. This will download a file on your computed. Zip this file. It is ready to be uploaded on Gargantext : click « add corpus », choose PubMed [XML] and choose the zipfile to upload.
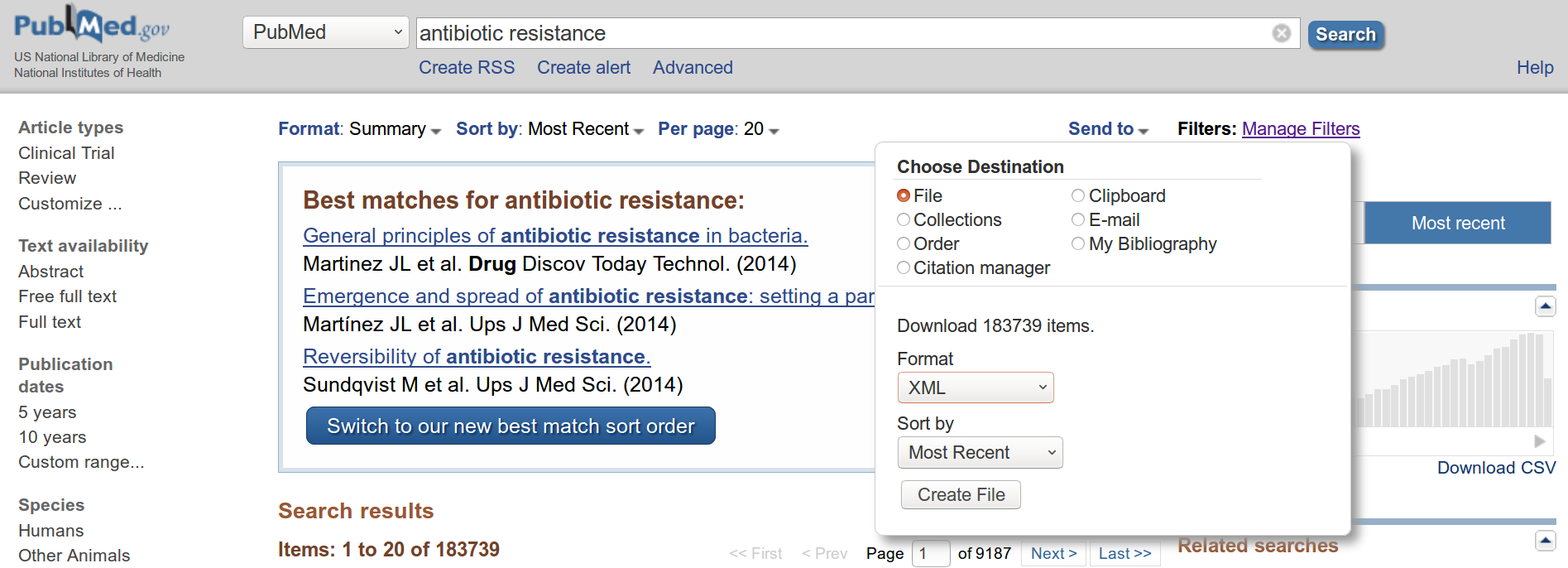
Screen shot of PubMed export page.
Zotero RIS Format
You can analyse the content of a Zotero library with Gargantext (titles and abstracts) with the following steps :
- In Zotero, select the documents to be exported
- Go to file > export library > RIS. This will produce a RIS file on your hard disc.
- Zip the file,
- Go to a project page, open the « add corpus » panel,
- Choose the RIS format and upload you zip.
- Launch the analysis. You will receive a mail when it will be done.

