
Formats d’import de Gargantext
Version 3.X
![]() Voir en anglais
Voir en anglais
Pour tout type d’import
Les fichiers de corpus doivent être téléversés au format d’archive compressée zip (.zip). Que vous ayez un ou plusieurs fichiers, vous devez tous les zipper dans une même archive (cela permet d’économiser de la bande passante).
L’import de corpus marque le début d’une analyse, il s’opère depuis la page listant les projets :
http://gargantext.org/projects
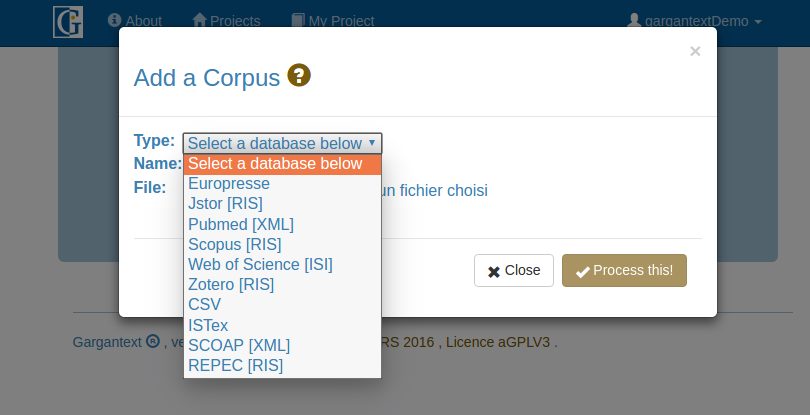
Description des types d’import
CSV
Le format CSV de Gargantext comporte :
- Un jeu de caractère UTF8
- la tabulation comme séparateur de champ
- pas de délimiteur de champ.
Si votre CSV ne se charge pas – dépannage
- vérifiez que vous téléchargez bien un fichier zip
- vérifiez que votre csv est encodé avec des tabulations comme séparateurs. Parfois, votre éditeur de texte change sans avertir l’encodage,
- supprimer les tabulations qui ne sont pas des séparateurs de colonnes : ouvrir le document dans un éditeur de feuille de calcul, remplacer les tab (\t) par des espaces.
Quel éditeur utiliser ?
Il est fortement recommandé d’utiliser un éditeur de texte libre tel que LibreOffice ou OpenOffice, certains éditeurs propriétaires ayant tendance à imposer leur format CSV.
- Sous Open Office par exemple, lorsque vous ‘sauvez sous’ votre document, cliquer sur ‘éditer les paramètres du filtre’
 Puis choisissez les paramètres comme suit :
Puis choisissez les paramètres comme suit :

- Sous Excel
- Ouvrir le fichier avec Excel en sélectionnant toutes les cellules (sélectionner la première cellule puis Ctrl+A, ou Cmd+A sous Mac)
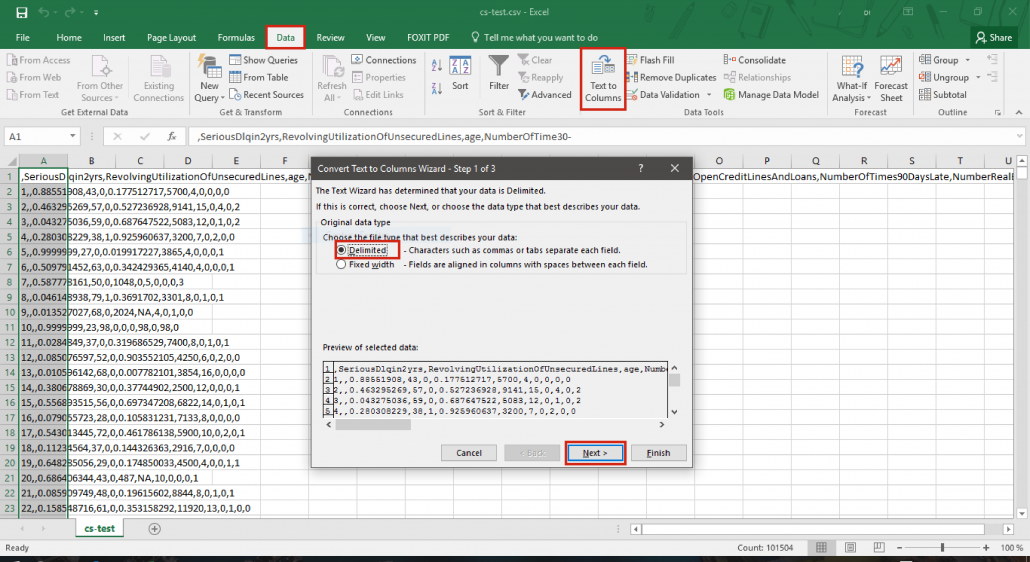
- Enregister le fichier en spécifiant qu’il s’agit d’un fichier au format CSV (.csv)
- Ouvrir le fichier avec Excel en sélectionnant toutes les cellules (sélectionner la première cellule puis Ctrl+A, ou Cmd+A sous Mac)

Le fichier lui même doit comporter les champs suivants avec une première ligne d’entêtes décrites entre crochets :
– titre du document [title]
– contenu du document [abstract]
– date du document [publication_year]
– auteur [authors]
– source du document (ex : le titre du journal) [source]
– mois de la publication (si pas indiqué, mettre le chiffre ‘1’) [publication_month]
– Jour de la publication (si pas indiqué, mettre le chiffre ‘1’) [publication_day]
En cas de doute, vous pouvez obtenir un exemple de fichier CSV Gargantext au format le plus récent en exportant votre corpus depuis la page ‘Document’ d’un projet.
Web of Science (ISI)
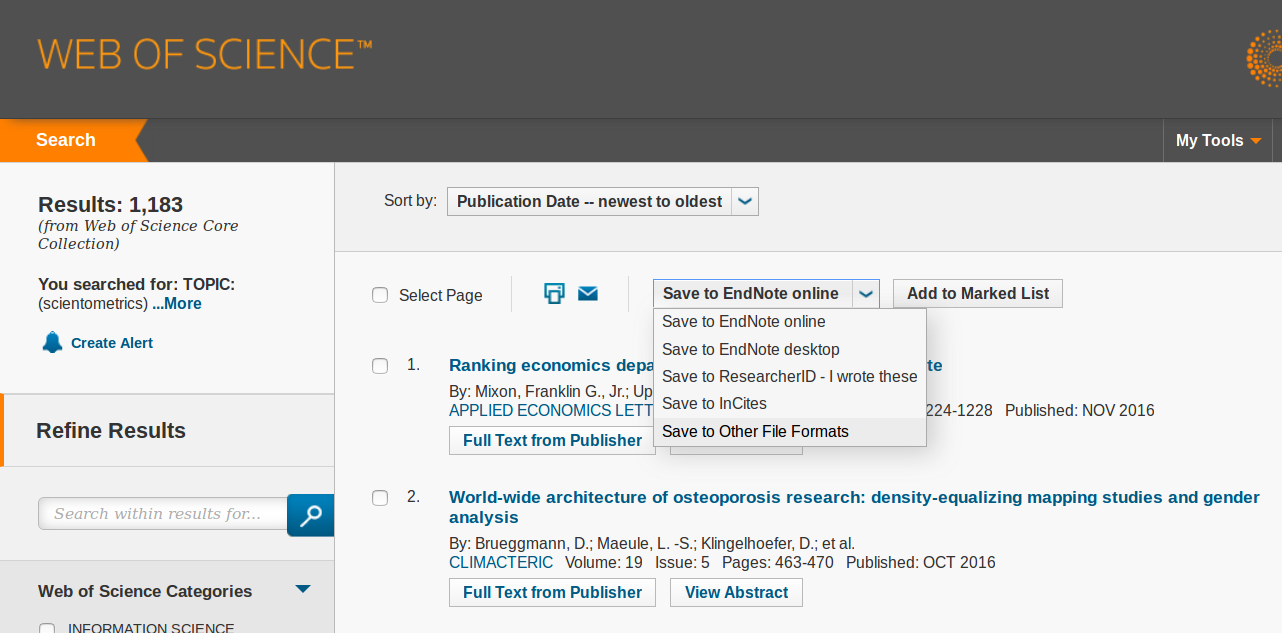
Les personnes disposant d’un accès au Web of Science peuvent exporter le résultat de leur recherche pour l’analyser dans Gargantext.
Sur la page des résultats de recherche, choisir ‘save to other file format’
Puis choisir les champs comme suit :
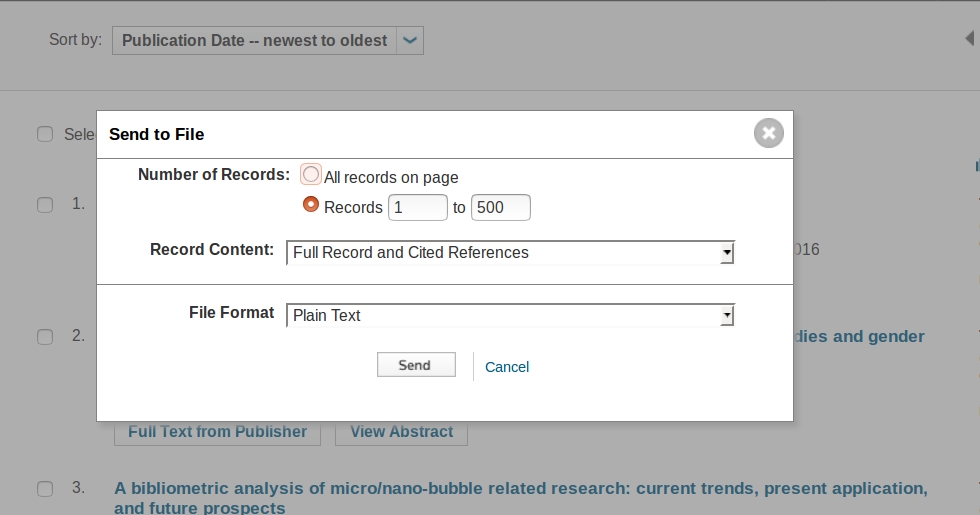
Compresser l’ensemble des fichiers ainsi obtenus avant de les téléverser sur Gargantext.
PubMed
PubMed est la plus grande base de données de résumés scientifiques et médicaux ouverte hébergée par le National Center for Biotechnology Information. Vous pouvez analyser un ensemble de métadonnées d’articles de PubMed à l’aide de deux méthodes distinctes :
- demandez à Gargantext de récupérer les 1000 derniers éléments correspondant à votre requête (sélectionnez « PubMed[XML] » dans le menu déroulant d’ajout de corpus),
- Télécharger vous-même un fichier zip d’un export PubMeb à partir du site Web de la NCBI. Dans ce cas, vous pouvez analyser jusqu’à quelques dizaines de milliers d’articles (au-dessus de 40k, vous aurez des problèmes côté client sur les versions Gargantext 3.x). Pour exporter des articles depuis PubMed, entrez une requête dans la page de recherche, puis cliquez sur « Send to > File > Format XML » et choisissez le fichier zip à télécharger comme dans l’image ci-dessous. Ceci téléchargera un fichier sur votre ordinateur. Zippez ce fichier. Il est prêt à être téléchargé sur Gargantext : cliquez sur « add corpus », choisissez « PubMed [XML] »
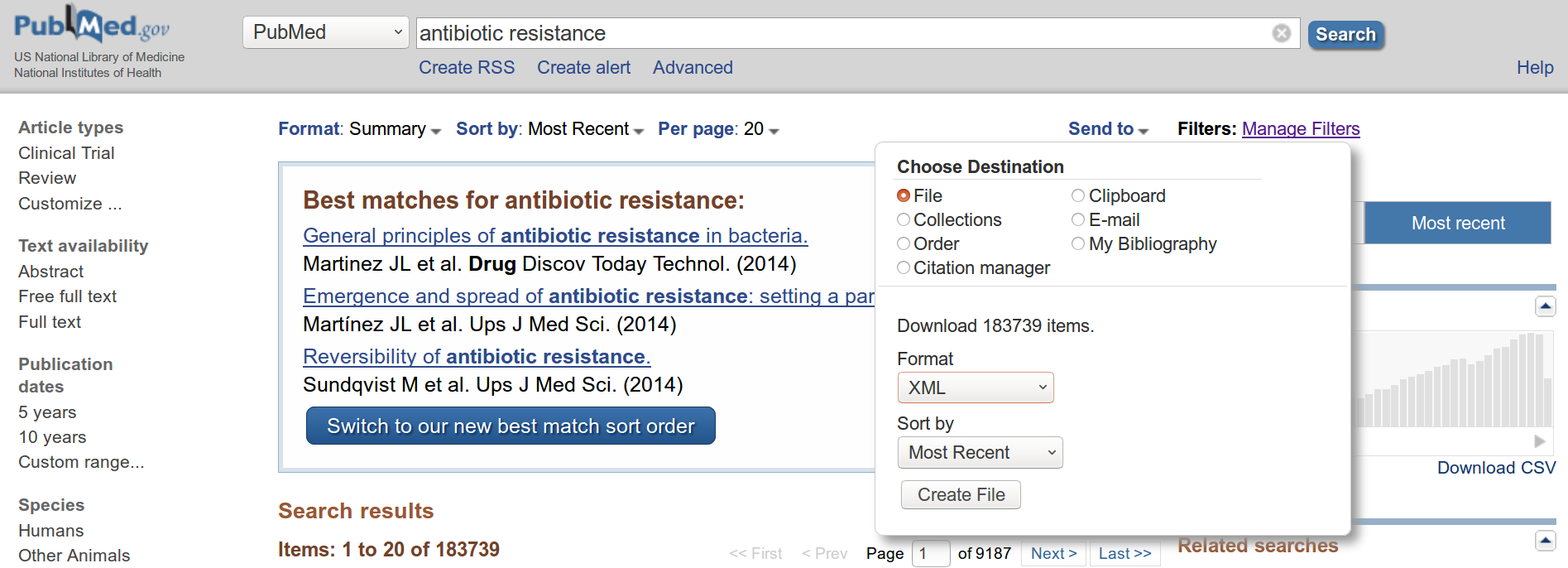
Screen shot of PubMed export page.

