
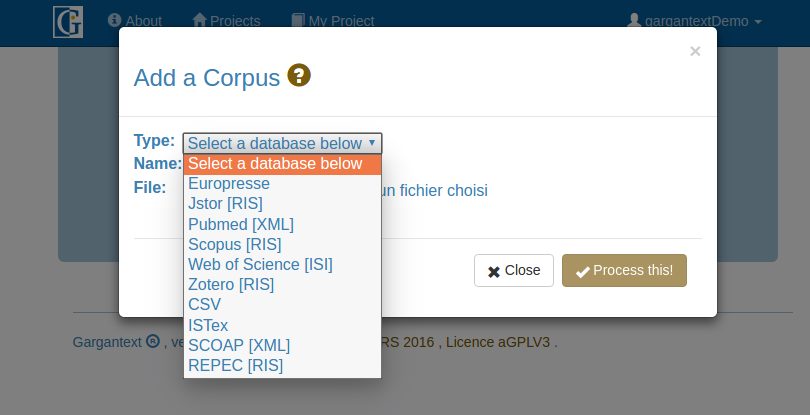
Importer un corpus via une API
Dans Gargantext, il est possible de téléverser son propre corpus ou de demander à Gargantext d’aller lui-même chercher un corpus correspondant à une requête dans une base de données par l’intermédiaire d’APIs.
Le champ « query » dans Gargantext reprend la syntaxe des API des différents fournisseurs de données et permet des requêtes plus ou moins sophistiquées. Par exemple pour ISTEX, la syntaxe « abstract:my_query » permet de n’importer uniquement les documents contenant la requête dans leur résumé. Ces comportements sont décrits dans les doc respectives des APIs.
Au 25 septembre 2017, les bases suivantes étaient disponibles via une API (possibilité de constituer son corpus directement depuis Gargantext) :
- PubMeb : principale archive de la recherche bio-médicale
- Istex : base de données documentaire interdisciplinaire du CNRS, regroupant Web of Science, Elsevier, etc. Mise à jour jusqu’au 3 dernière années. /!\ Attention, l’API ISTEX fait une recherche dans les méta-données et le full text mais seules les méta-données (titre, résumé) sont analysées par Gargantext. Le nombre de documents associés à une recherche peut donc être différent dans la résultat de l’API et dans le corpus téléchargé.
- SCOAP : archives pour la physique des particules
- REPEC : archives académique de la littérature économique
- HAL : archives communes à plusieurs établissements de recherche français.
- ISIDORE (beta) : accès unifié aux données de la recherche dans les sciences humaines et sociales.






Laisser un commentaire
Rejoindre la discussion?N’hésitez pas à contribuer !