

EPIQUE
A comparative analysis and quantitative understanding of sciences evolution.
The development of new types of socio-economic activities on digital media led to the constitution of huge electronic corpora that are one of the major components of the Big Data revolution in humanities and social sciences.
Such corpora are both a reflection and, perhaps even more importantly, a crucial part of the ubiquitous processes of distributed knowledge creation constantly occuring in many contexts: scientific communities, patent and technologie networks, online collaborative platforms, blogs, wikis, etc.
In parallel, we can witness an intense activity in mathematics and computer sciences toward Big Data analysis with the development of high performance computing and data processing platforms as well as new methods to perform text-mining or complex and multiplex networks analysis.
The combination of these two major trends paves the way toward large scale analysis of large digital corpora, which bears on significant scientific challenges in several fields including linguistics, distributed processing, complex networks analysis and information visualization.
The EPIQUE proposal focuses on scientific corpora and aims at overcoming several challenges that remain on the way to a comparative analysis and quantitative understanding of sciences evolution as a whole.
While part of the proposed researches will specifically take advantage of the structure and content of scientific documents (citations link, co-authorship, key words, significant expressions, etc.) most of them will be conducted so as to be as generic as possible, with applications far beyond science to other kinds of corpora such as those mentionned above (web, patents, newspapers, etc.).
Understanding Science evolution
The reconstruction of the structure and evolution of science in a bottom-up way from scientific production is of utmost importance for a wide range of actors :
- epistemologists and historians of science, who need to test their theories with data, in particular about the ways fields cross-fertilize and novelty emerge,
- scientists who want to position themselves in their field, understand the ins an out and find domains with high discovery potential,
- policy makers who want to spot emergent fields, foster innovation and get key indicators to assist them in decision-making processes,
- industry, that have to find its ways through the scientific production and evaluate the potential for innovation and technological transfert,
- librarians who need to propose classifications of documents which respect not only scientific topics hierarchy but also the evolution of ideas.
Context
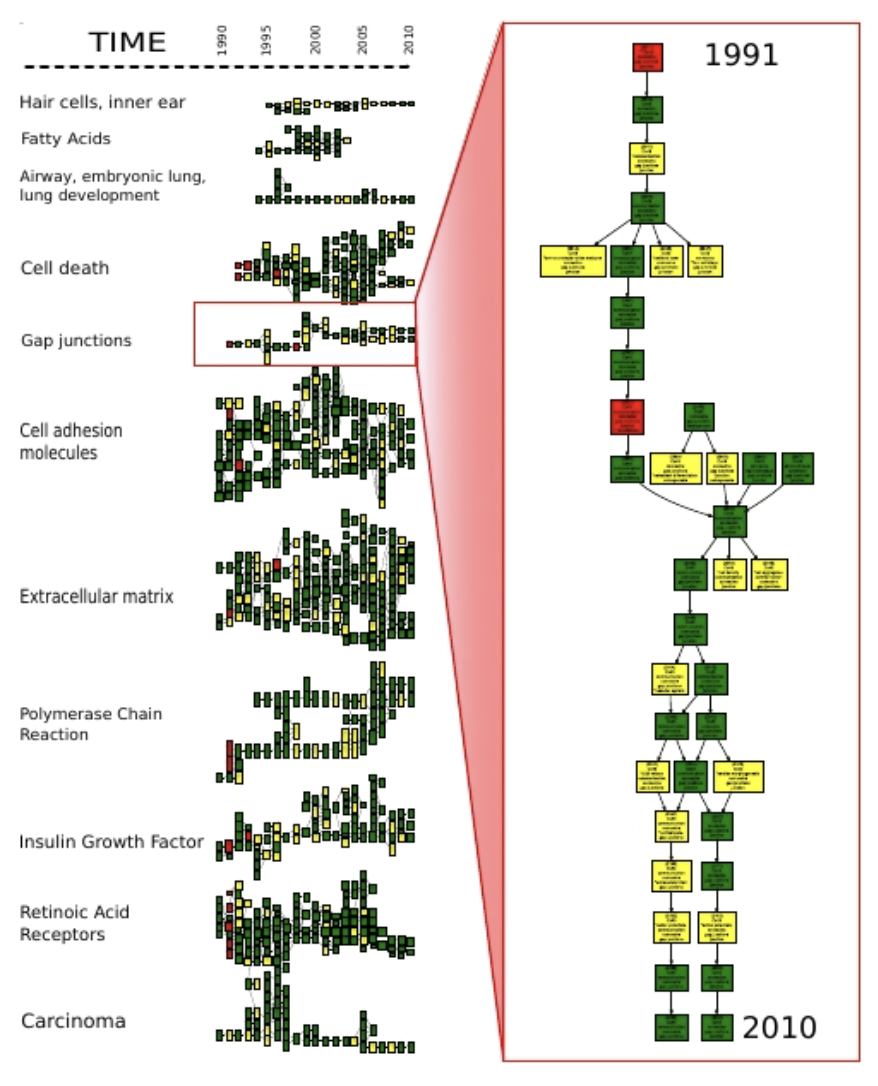
The EPIQUE proposal is situated in the context of the French national CNRS interdisciplinary research initiative MASTODONS (Grandes masses de données scientifiques) ARESOS. Its starting point is the work of David Chavalarias (CAMS-CNRS,ISC) and Jean-Philippe Cointet (INRA-SenS,ISC) on the conceptual analysis of evolving document corpora (blog, forum, bibliography collections, document archives) through the construction of phylomemetic trees representing the temporal evolution of topics inferred from a set of document archives covering a large timespan (the notion of phylomemetic tree is inspired from the notion of phylogenetic tree representing the characteristics and evolution of species and derived from the genes of their members).
Objectives
Our first goal is to build a global semantic map of the evolution of science by applying appropriate scientometric models on the WoS corpus including more than 600K terms and the scientific publications over the last 20 years. This objective will be the general driving force for the project and represent the main experimentation and validation criteria for the other objectives.
The second objective directly follows from the previous goal. The size of the WoS corpus represents an important challenge which needs the development of new solutions exploiting recent parallel data processing frameworks like Hadoop, Spark, Hadoop, Pregel, Terrier. The project partners already have some first promising results in using Spark [Laj2014, Gui2014] for building phylomemetic trees over the WoS corpus. Our goal is to go further in defining appropriate scalable data structures and algorithms for analysing and combining textual and semantic contents and metadata.

You must be logged in to post a comment.