PREVIOUSLY ON MULTIVAC
A while back we released Multivac Platform (2.0). The goal was to make our large-scale datasets available to scientists and research engineers in the most convenient way. Therefore, we introduced a service called “Multivac APIs” that offers comprehensive REST APIs to access available datasets (over 200 million documents and counting). Yes, and counting! Most of our datasets are originated from real-time data streaming services like Twitter.
In addition to making RAW data available, we did our best to meet most of the needs to provide aggregated API endpoints for all available datasets. This helps our users to save time, storage and computations by simply using aggregated results of their queries.
Featured projects powered by Multivac
“Since the release of Multivac Platform 2.0 we have reached up to 70 users, 6 projects and over 200 million data has become available”





As useful as “Multivac APIs” service is to overcome difficulties of accessing real-time large-scale datasets on the go, we know it may still not cover all use cases.
Imagine the following scenarios:
Scenario #1: You need access to millions of data stored in Multivac at once so you can run your own code/algorithm.
Scenario #2: Let’s assume you already have your own datasets and all you need is to use Multivac infrastructure to run your jobs.
In both of scenarios you are facing common problems:
1. Storage: Simply where to store all that data.
2. Computation: Hard to believe a laptop can handle complicated algorithms that require hundreds of iterations through millions of data.
Now sounds like we are looking for a special type of computational cluster designed for storing and analysing huge amounts of data such as Hadoop with engine for large-scale data processing such as Apache Spark implemented over many servers in Cloud where you can fire up your jobs in Scala/Java/Python/SQL and R.
We’ve built a whole bunch of stuff to bring Data Science and Big Data hand to hand right to your doorstep.
INTRODUCING MULTIVAC “DATA SCIENCE LAB“

Multivac Big Data Architecture
We have designed and implemented Hadoop cluster over more than 30 servers inside our private Cloud. This gives us Hadoop YARN and Hadoop HDFS to manage all resources with distributed storage over all those machines (highly available, fault tolerance, etc.). We have also implemented Apache Spark (+1.6, 2.2) on top of our Hadoop cluster.
In addition, we have configured and implemented two Web-based notebooks Apache Zeppelin and Hue that enable data-driven, interactive data analytics, and visualisation. They also support multiple languages, including Scala, Spark SQL, Python, R, Hive and Markdown. Apache Zeppelin and Hue also provide Apache Spark integration making it possible to take advantage of fast in-memory and distributed data processing engine to enhance your data science workflow.
We believe this makes Big Data development and data science much easier for any research project dealing with large-scale data.
We have done our own studies in the field of Data Science focusing on Machine Learning and NLP for the past few months. We have used Multivac “Data Science Lab” for the followings:
- Un-supervised Machine Learning
- Clustering (Wikipedia, Tweets, etc.)
- LDA
- k-means
- Clustering (Wikipedia, Tweets, etc.)
- Semi-supervised Machine Learning
- Graph-based algorithms (economic dataset, movie ratings, etc.)
- Supervised Machine Learning
- Regression
- Classification
- Collaborative Filtering
- Alternating Least Squares (ALS)
- Natural Language Processing (NLP)
- Stanford CoreNLP with massive amount of data
For instance, we have done some works in NLP at scale by using Multivac DSL. We have constructed Part of Speech and extracted chunk of phrases from 19 million scientific abstracts (PubMed database) within 8 minutes to use it in our LDA studies.
Notebooks and Multivac APIs
Easily use Multivac APIs in your notebooks!


Visualise Your Data
Easily visualise your data before diving into any Machine Learning algorithms

Machine Learning On The Go!
Create, edit, share your notebooks with your teammates! Each notebook can be used by multiple languages! Unlike Jupyter, you don’t have to stuck in one language 🙂


Simple Twitter Analytics
Let’s see a simple and quick example of how to analysis some Tweets by using “Multivac DSL”. For this tutorial I am going to login to Apache Zeppelin hosted by Multivac with my ISC-PIF/CNRS LDAP account. (ISC-PIF LDAP account is used to access all of our services and machines to simplify the process and eliminate having multiple accounts)
So I am going to request my Twitter archive from my profile. Once this request has been sent it will be processed by Twitter and you will receive a link to download. As you can see it in the screen shot, I simply upload the file I need to access in my Spark application (tweets.csv).
Spark has the ability to easily read CSV or JSON file and make Spark DataFrame. So to recap:
- Read tweets.csv into Spark DataFrame
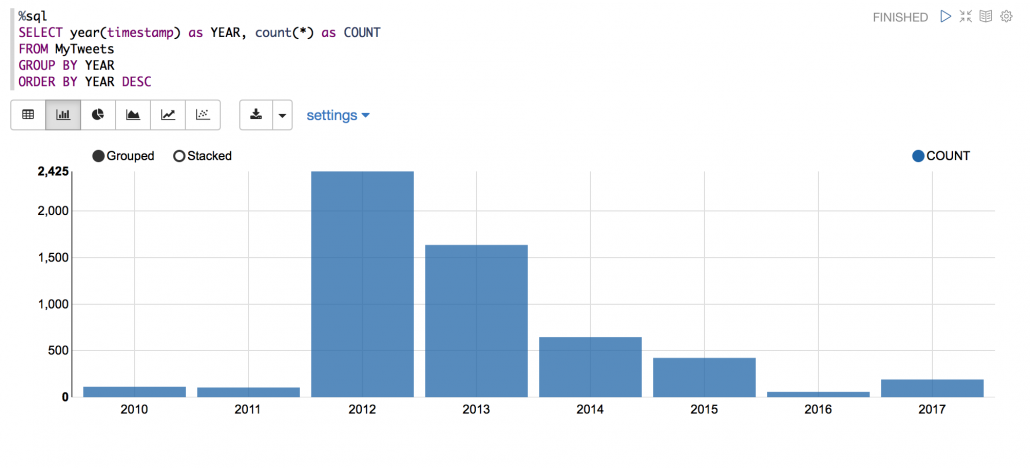
- Visualise my Tweeting activities by each year
- Clean the “source” field for better understanding
- Visualise the source of each tweet to find anything useful (I used Flipboard a lot back in 2012!)
- A simple word processing to count everything I have ever tweeted
If you are interested you can find more tutorials here 🙂















CALL FOR PARTICIPANTS

Moving forward from this point we need to deal with more diverse use cases and more users to be ready by the end of 2018 when we will open Multivac Data Science Lab to all of our partners.
Therefore, we are looking for small to medium size research projects focusing and entirely relaying on Apache Spark (Scala, Java, Python, SQL and R). If you are interested to become a participant please read the followings and submit the form.
- Apache Hadoop
- Cluster (YARN – distributed over 30 servers)
- Allocated Resources
- 50 cores of CPU (dedicated)
- 50GB of memory (dedicated)
- Supported services
- Apache Spark 2.2 (Scala, Python and R)
- Apache Hive
- Allocated Resources
- Storage (HDFS – distributed over 30 servers – replication factor 3)
- +2TB HDFS to an individual
- +10TB to a team
- Scientific Notebooks/Dashboards
- Apache Hue (hosted by Multivac)
- Apache Zeppelin (hosted by Multivac)
- You can also connect your RStudio directly to Spark cluster!
- Cluster (YARN – distributed over 30 servers)
- Access to Multivac APIs with over 100 million data
- Access to Machine Learning code repositories
- 2-day Hadoop Training (Spark, Hive, HDFS, Kafka, Hue, Zeppelin, etc.)
- Support by ISC-PIF engineers / data science interns
- Participate in meetings when it’s required
- Write short stories about your experience on our blog
- Present your work at ISC-PIF Seminar
- Use open source and stay open source!
- Acknowledge ISC-PIF/CNRS in your publications
- Submission: End of October 2017
- Results: End of November 2017
- Meeting and coordination: December 2017
- Start: 1st of January 2018
- End: 30th of June 2018
- Submission is open only to ISC-PIF Partners
- You are only allowed to use Spark to run your computations. At the moment we do not support nor accept any other Hadoop application that runs by MapReduce (Pig, Oozie, Java, etc.).
- You are not allowed to run Ad-Hoc computations. All the candidates must run their codes/applications through provided Notebooks (connected by Apache Livy), Spark shell, or Spark submit.
- However, you are more than welcome to import any external library compatible with Spark environment to enhance your research project:
- Apache Mahout
- TensorFlow (Python and TensorFrame for Scala)
- H2O Sparkling Water
- etc.
- The current Hadoop cluster does not support GPU. All your codes (ex. ML or Deep Learning) will be executed over CPU.

Submit Your Proposal
submission is closed!


Vous devez être connecté pour poster un commentaire.