Innovatives Big Data : la valeur des données
Le 13 octobre dernier, l’équipe de l’Institut des Systèmes Complexes ISC-PIF à participé en tant qu’exposant au Forum des Innovatives Big Data, une journée organisée par le CNRS afin de porter à la connaissance des entreprises les innovations de ses laboratoires, souligner la dynamique des partenariats avec le monde socio-économique.
 Armés de posters et de démos, nos chercheurs ont présenté la dernière version de Gargantext, Blue Jasmine, dont l’objectif est de permettre à tout étudiant et chercheur de générer, en quelques clics et sans connaissances préalables en text mining, une cartographie de connaissances ou des états de l’art. Cet événement d’envergure à également été l’occasion pour nous de faire connaître notre plateforme Multivac auprès des chercheurs. Cet outil développé par nos ingénieurs à l’ISC-PIF aide la communauté scientifique à surmonter les challenges posés par le big data, ou métadonnées.
Armés de posters et de démos, nos chercheurs ont présenté la dernière version de Gargantext, Blue Jasmine, dont l’objectif est de permettre à tout étudiant et chercheur de générer, en quelques clics et sans connaissances préalables en text mining, une cartographie de connaissances ou des états de l’art. Cet événement d’envergure à également été l’occasion pour nous de faire connaître notre plateforme Multivac auprès des chercheurs. Cet outil développé par nos ingénieurs à l’ISC-PIF aide la communauté scientifique à surmonter les challenges posés par le big data, ou métadonnées.
Voir l’article sur Multivac sur le site du CNRS
Quelle valeur pour les données?
David Chavalarias, Le directeur de l’institut, était par ailleurs invité comme intervenant à s’exprimer sur la question suivante : « Quelle valeur pour les données ? ». Avec 400 000 requêtes par secondes sur Google, et des centaines de millions de messages échangés par minute, le monde est aujourd’hui noyé dans les informations textuelles. Or, celle-ci ont une valeur particulière, notamment aux yeux des chercheurs en systèmes complexes, car ces données analysées dans leur ensemble fournissent un panorama des transformations qui s’opèrent dans le monde, à différentes échelles, et dans différents domaines. Dans les sciences, c’est plus d’1,5 millions d’articles qui sont publiés par an ; ce sont autant de données qui peuvent être analysées pour trouver de nouvelles formes d’interactions avec les masses de données textuelles et créer de nouvelles connaissances.
Télécharger les slides de l’intervention
Risk Research : le big data au service de la compréhension des risques

D. Chavaralarias et R. Gusdorf sur la scène des Innovatives Big Data, 12 octobre, CNRS.
Accompagné de Raphaël Gusdorf, responsable de la sélection et des partenariats au fonds AXA pour la recherche, David Chavalarias à présenté le projet Risk Research, une collaboration entre l’ISC-PIF et le fond AXA pour la recherche qui s’appuie sur le big data pour cartographier et mieux cerner les interactions entre les risques. Dans ce contexte, 30 000 articles portant sur le thème du risque ont été analysés par un traitement de langage naturel, ce qui a permis d’identifier environ 5000 termes liés au risques. L’évolution temporelle de ces 5000 termes a ensuite été étudiée à travers plus de 50M de publications du Web of Science afin de dégager des sous-catégories ainsi que des tendances à différentes échelles de temps. Les résultats obtenus sont visualisés sous forme de graphe interactif, ce qui permet de voir en un clin d’œil les thèmes et tendances autour de la notion des risques.
Comme l’explique Raphaël Gusdorf, la cartographie de la connaissance liée aux risques est un enjeu essentiel dans la structuration de la réflexion sur les limites d’interventions de l’assureur. Ce projet a permis de constater par exemple que les thématiques liées aux risques qui sont au cœur de l’action d’AXA, à savoir l’environnement, la santé, le contexte socio-économique et la révolution digitale, ne sont pas reflétées tels quels dans la littérature scientifique. Grâce à ce constat, l’assureur peut initier une réflexion sur les meilleurs moyens de réconcilier la manière dont il parle de ce qu’il fait dans une sphère d’entreprise avec la manière dont les scientifiques parlent des mêmes sujets.
La carte “Risk Research” est développée en Open Source, et accessible au grand public, notamment à la communauté des chercheurs qui bénéficient de formations gratuites dispensées à l’institut. Dans un futur proche, de nouvelles sources telles que Wikipédia et Twitter seront intégrées à ce type de carte avec pour objectifs de mieux identifier l’évolution des risques et leurs émergences.
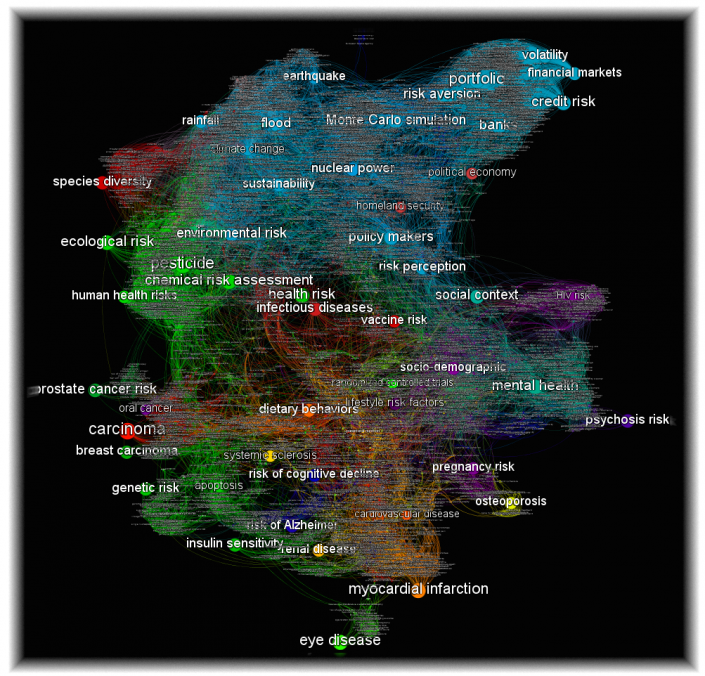
Mapping Risk Research, une collaboration ISC-PIF et fond Axa pour la recherche.


Vous devez être connecté pour poster un commentaire.